

The Challenge of AI Identity
AI-generated characters are everywhere now — from virtual influencers and short films to interactive stories and social posts. But while it’s easy to generate a character, keeping that character consistent across scenes and media. That’s a different beast.
Most diffusion models are great at one-shot creativity, not memory. You’ll get a great first image, but when you ask for a second frame? The eyes shift color. The hair grows longer. The vibe changes. The result: a fractured story and a confused viewer.
So, how do we get around this? How do we make sure our characters look and feel the same — even as they move through different scenes, angles, or emotional beats?
Turns out, it’s not just about the model. It starts with the prompt.
Why One Prompt Isn’t Enough
Here’s a familiar scenario: you describe a character —
Prompt Structure:
Milo, cheerful robot, teal eyes, metallic body

The first frame gets it exactly right. However, by frame two, Milo suddenly began to look oddly human.
This isn’t a bug. It’s how diffusion models work unless you give them strong, structured guidance. What they need is a sense of identity — an anchor to hold onto. And that’s something you can design for, not just hope for.
Prompting Is Design
Forget “write a prompt” — think “design a prompt.”
A good prompt is like a blueprint. It tells the model what matters and in what order. Structure is key. Here’s a format that works reliably:
Identity + Core Traits + Clothing/Style + Pose + Lighting/Camera + Background
Examples:

These prompts are repeatable across frames or poses by keeping the identity block consistent and only adjusting pose, camera, or lighting when needed.
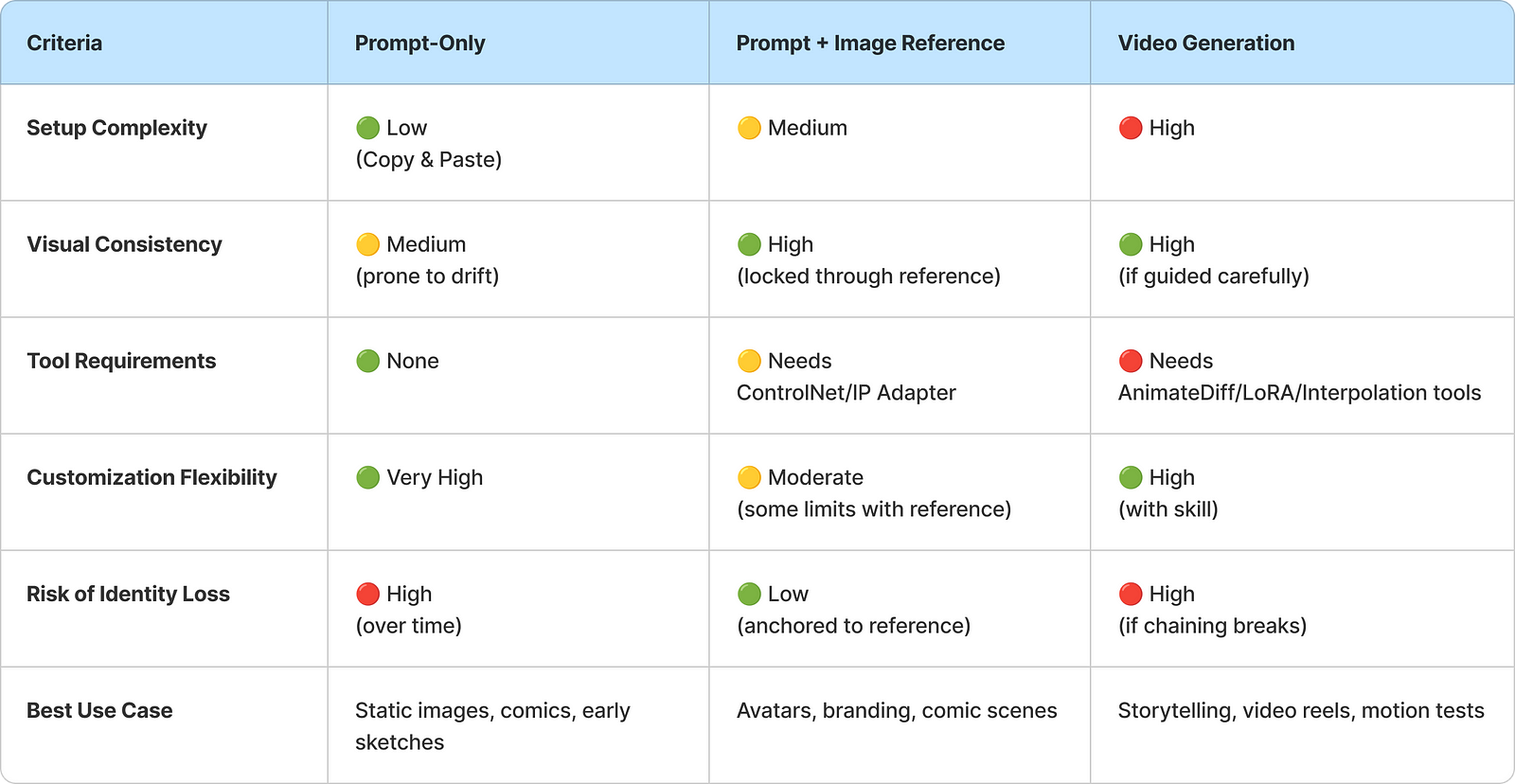
Three Paths: With or Without Images and Video
When generating consistent AI characters — whether for comics, videos, branding, or storytelling — your strategy will fall into one of these paths:
1. Prompt-Only (Text-based consistency)
This one’s about discipline. It depends entirely on structured prompts — uniform phrasing, consistent variables, and no visual references. It’s ideal when you’re starting from scratch or developing a comic where minor visual inconsistencies are acceptable. The key is using precise, disciplined language to define and maintain character identity.


Tips for Maintaining Consistency:
Repeat key phrases exactly: Use precise, consistent wording like “brown trench coat” instead of switching to “coat” or “jacket”.
Specify fixed visual traits: Say “cybernetic eye on the left side” rather than just “cybernetic eye”.
Lock the camera setup: Add details like “50mm lens, low-angle shot” to keep framing consistent.
Control lighting and mood: Use phrases like “dramatic cinematic lighting, volumetric fog” to stabilize tone.
Be consistent, not just descriptive: Avoid introducing synonyms or extra adjectives unless variation is intentional.
2. Prompt + Image Reference
This approach pairs a reference image with a prompt, effectively telling the model, “Look like this, but do this.” The image acts as a visual anchor — such as a character portrait, sketch, or render — while the prompt guides pose, style, or narrative, resulting in greater visual consistency, especially useful for animation or branded content.

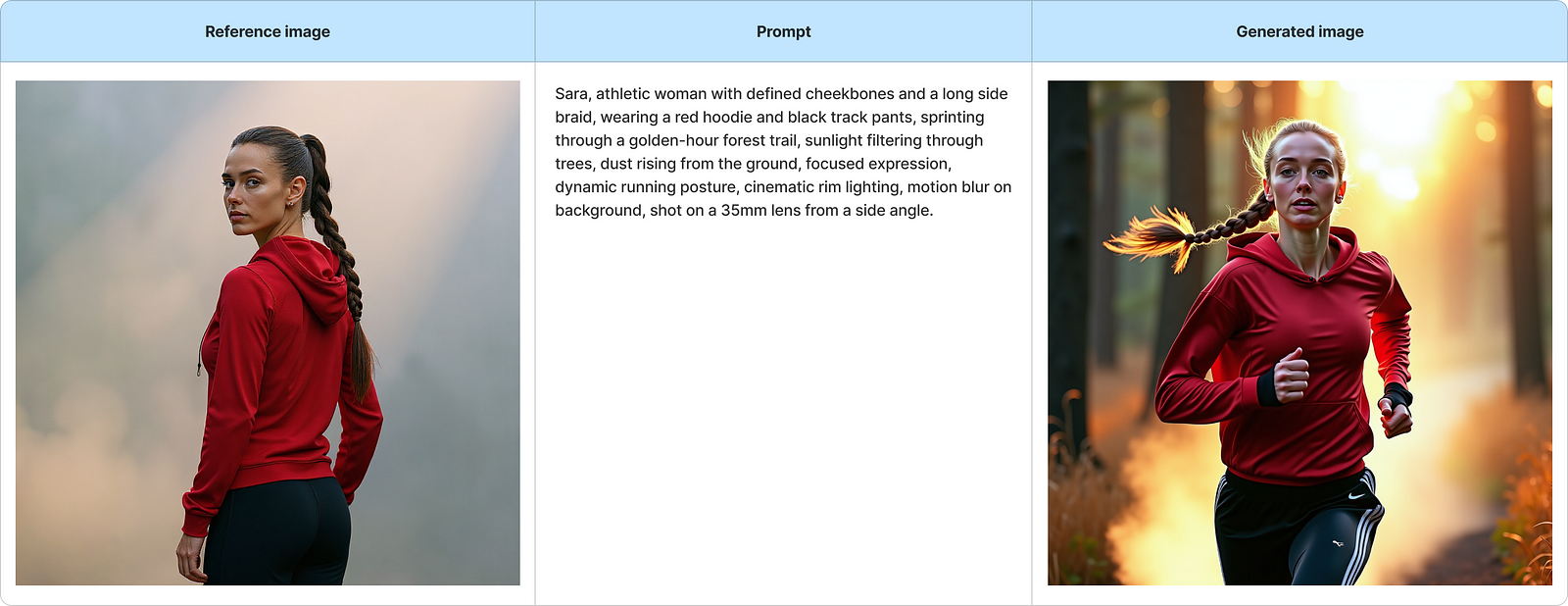
Tips for Best Results:
Keep the reference image consistent throughout your project
Use IP Adapter for loose matching or ControlNet (Face/Pose/LineArt) for tighter control
Ensure the prompt doesn’t contradict the image (e.g., don’t say “ponytail” if the reference has a braid)
3. Video Brings a New Layer
Here, you’re not just creating consistent images — but ensuring those images flow smoothly in a timeline. This adds a layer of complexity: continuity.
When generating videos with AI, the challenge multiplies: it’s not just about making each frame look good, but ensuring every frame connects fluidly to the next. Even the slightest mismatch — like a flickering eye color or shifting hairstyle — can break the illusion of consistency. That’s where smart planning, anchoring, and fine-tuning come in.
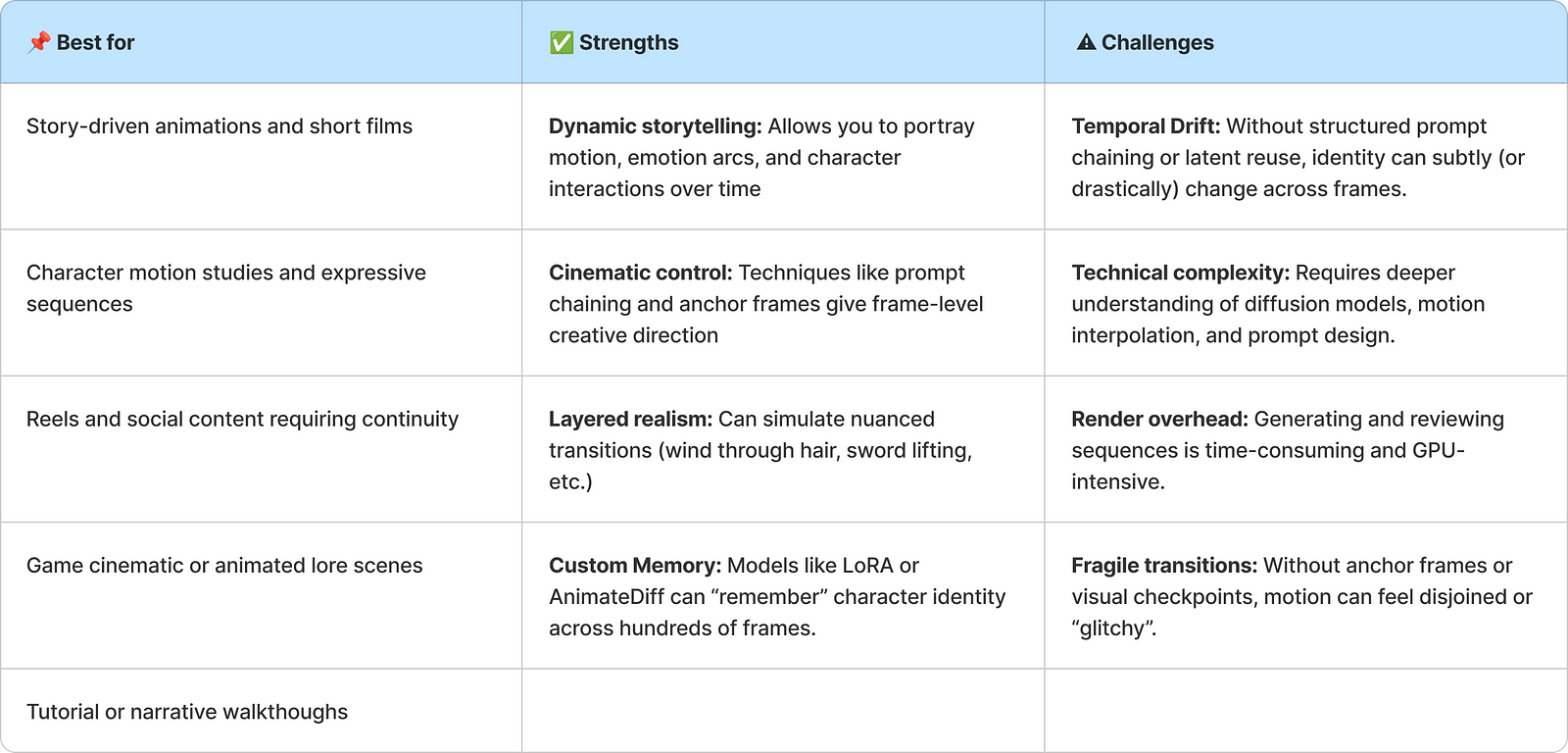
Core Strategies
Key techniques to ensure consistent, expressive, and smooth character animation across frames.
Anchor Frames
Create a few key frames with locked style, pose, and emotion. Use them as guideposts across the animation.Prompt Chaining
Gradually change only 1–2 elements per frame to create believable motion.Latent Reuse
Preserve character features in the latent space across frames for cohesion. Works well in advanced workflows like AnimateDiff.LoRA Training
Train a LoRA (Low-Rank Adapter) model on your character so the model remembers them deeply. Great for long videos.
Example:
Prompt Chaining for Video: Ava the Warrior Elf
Objective:
Generate a short, visually consistent video of Ava, a warrior elf, in a dramatic sword-lifting scene using diffusion models with prompt chaining + latent reuse.
Identity Anchor (Core Description for All Frames):
Ava, a tall warrior elf with long silver hair, sharp green eyes, wearing a dark leather armor with silver accents, in a moonlit forest clearing, cinematic lighting, rim light on edges, 50mm lens
This description is repeated in every frame, with only the action/pose/motion slightly altered to preserve identity

Optional Enhancements:

This version not only preserves Ava’s identity and style but also adds depth through camera movement, lighting consistency, environmental interaction, and micro-gestures, crucial for smooth video interpolation or animated storytelling.
Tips for Consistency in Video Prompts
Repeat identity and style phrases exactly in all frames (“long silver hair”, “dark leather armor”, “moonlit forest”)
Keep camera details fixed or only slightly vary (e.g., same lens, slight tracking pan)
Add motion gradually — avoid drastic pose or lighting changes
Use anchor frames (Frame 1 and Frame 5) to guide interpolation tools or video models
Consistency in video is all about balance — enough change to create motion, but not so much that identity falls apart.
Comparison chart:
Pro-Tip: Which Path Should You Take?
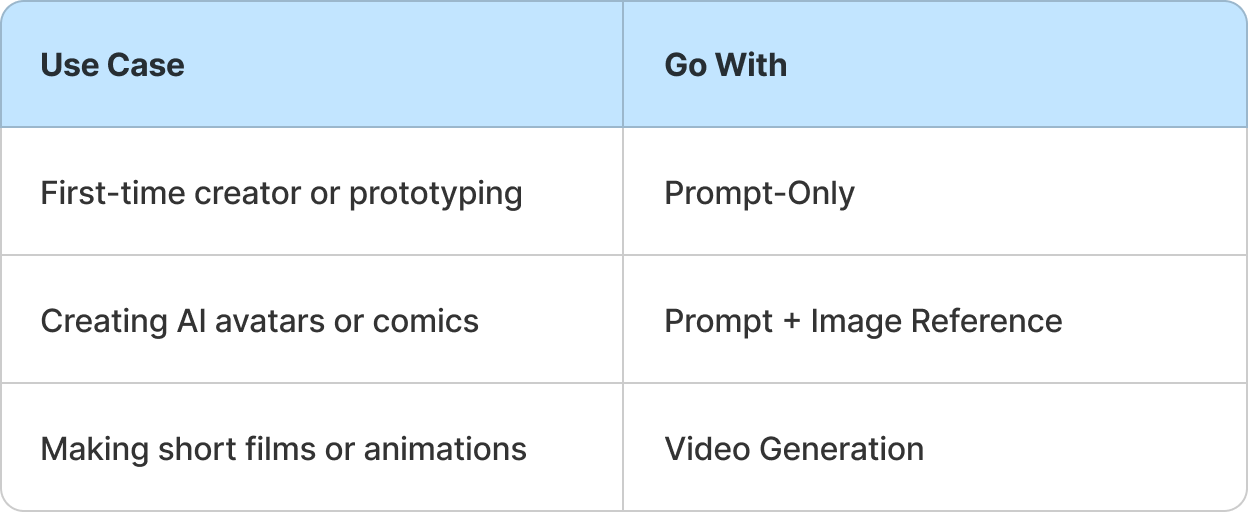
And remember:
You’re not stuck on one path. You can start with prompt-only, add a reference image later, and upgrade to video once you nail the character’s identity.
Why Diffusion Models Matter
Diffusion models don’t just generate images — they sculpt clarity from chaos. Starting with random noise, they progressively refine pixels through multiple steps, guided by your prompt, model parameters, and optionally, reference inputs.
But here’s what makes them powerful for keeping a character visually consistent:
1. Latent Control
These models operate in a latent space — a compressed, abstract representation of visual features. That means identity traits like hairstyle, outfit, or face shape can be deeply encoded and reused across generations.
Example:
If your prompt says:
Niko, a teenage hacker with messy red hair, silver glasses, and a navy hoodie

That identity can be baked into the model’s latent layers and reused across scenes, making it easier to reproduce Niko again and again.
2. Cross-Attention Mechanism
Diffusion models read prompts with attention layers that map words to pixels. This ensures that “silver glasses” or “navy hoodie” don’t just appear anywhere — they get placed where they belong on the character.
Example:
Writing structured prompts like:
Niko, crouching on a rooftop at night, navy hoodie covering red hair, looking down through silver glasses

Reinforces location-bound identity. Cross-attention ensures those visual traits are anchored to the character’s body parts (e.g., glasses on the eyes, hoodie on the head).
3. Conditioning Layers
With technologies like ControlNet, IP Adapter, or LoRA, you can guide generation using multiple conditioning sources:
Text (the prompt)
Image (a character reference)
Structural guides (pose, depth, outline)
These layers blend input types during generation, which helps preserve both form and identity — across poses, angles, or even videos.
Example:
Combine this prompt:
Niko, holding laptop while sprinting down a neon-lit alley

With a base image of Niko standing still in the same outfit, and pose extracted via ControlNet.
This layered approach ensures the holding laptop is new, but the identity remains fixed.
TL;DR:
If you’re trying to keep a character consistent across frames, styles, or animations, diffusion models help you:

And that’s why your model choice is just as important as your prompt quality — the right architecture gives your character memory, structure, and style.
Diffusion Models, ControlNet Variants & Character Consistency Strategies
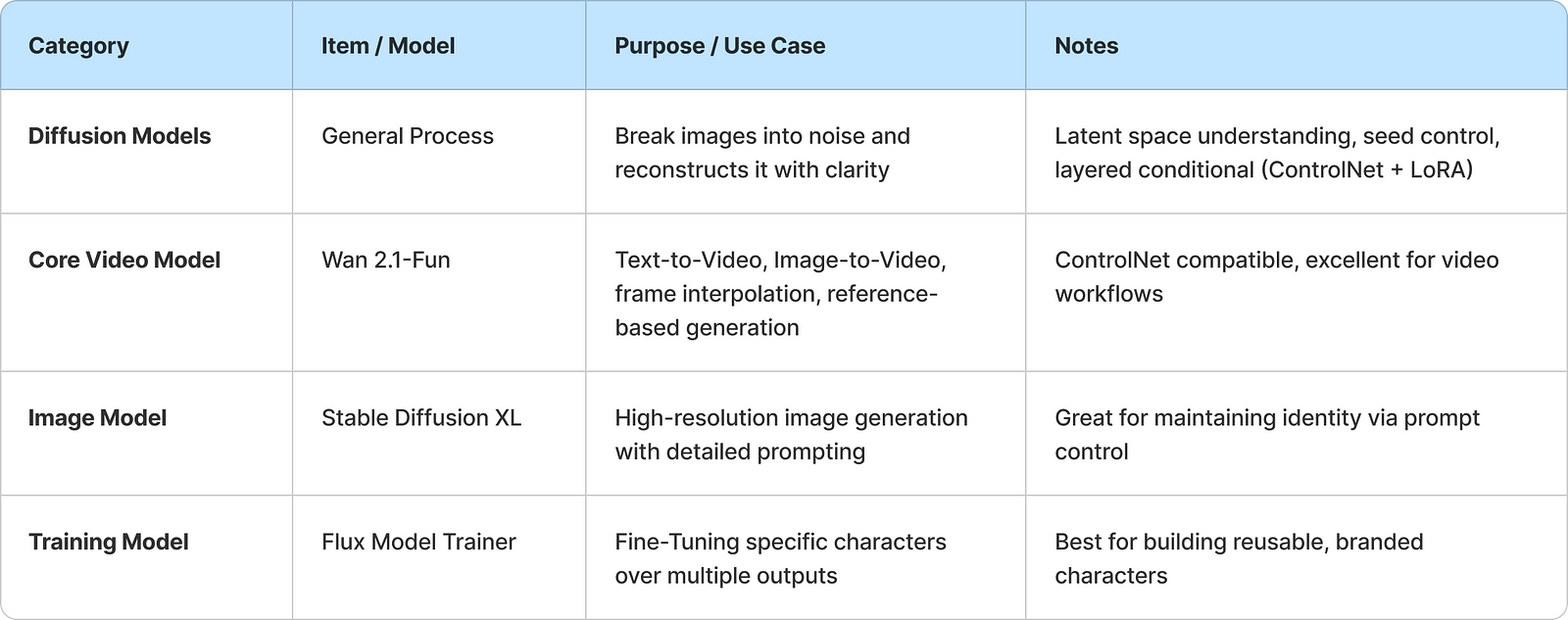
ControlNet Variants & How They Help
ControlNets are your best friend when it comes to making characters do what you want without changing who they are.
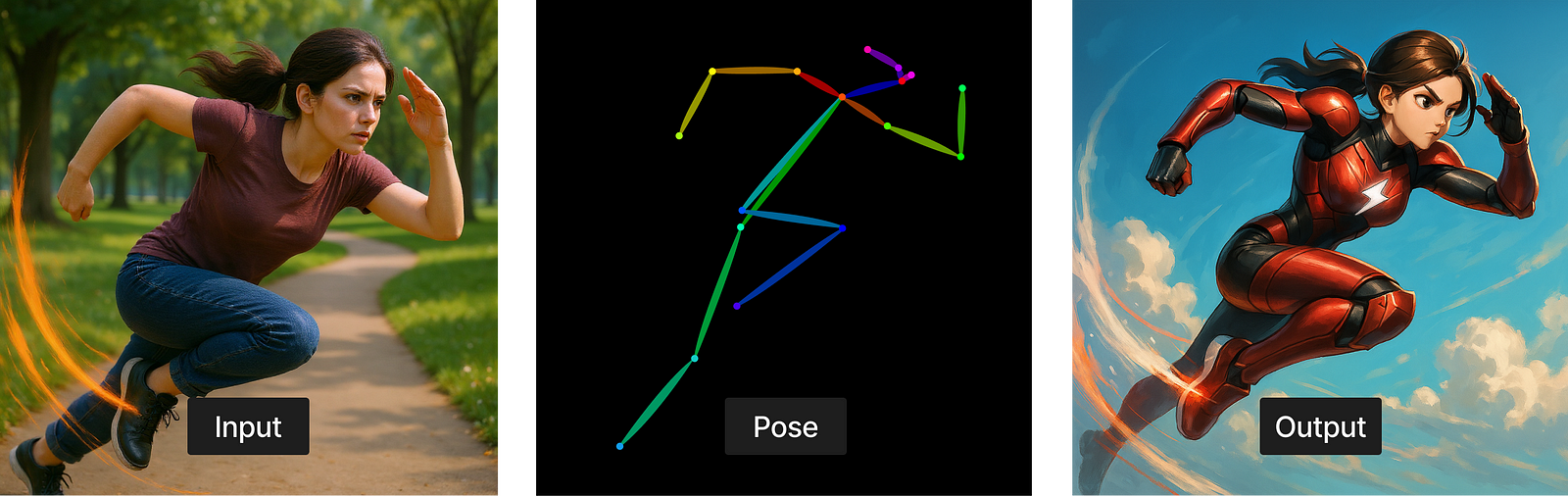
1. Pose ControlNet
Extracts skeletal pose and body structure
How it helps with consistency:
Enables full-body reorientation or transformation
Prompt:
A dynamic illustration of a female superhero sprinting at high speed through the sky, wearing a sleek red and black armored suit with a white lightning bolt emblem on the chest. Her brown hair is tied back in a ponytail, and she is surrounded by swirling wind effects against a bright blue sky with fluffy clouds, conveying a sense of power, motion, and determination.
2. Line Art ControlNet
Extracts outlines and strokes
How it helps with consistency:
Maintains visual identity and fine details from the original style
Prompt:
A young woman stands in front of a grand stone castle. She wears an ornate golden crown adorned with red jewels and a flowing, elegant pink gown featuring intricate gold embroidery on the bodice. A sheer, embellished cape drapes over her shoulders, adding a regal touch. The scene is set outdoors in soft, warm lighting, evoking a royal atmosphere.

3. Depth ControlNet
Captures depth and spatial relationships
How it helps with consistency:
Balances realism and structure without distorting the character
Prompt:
A stylish woman with long, sleek white hair, wearing round blue sunglasses and a vibrant oversized yellow jacket. Inspired by retro-futuristic 80s and modern pop-art fashion

Combined Workflow Tips for Consistency
These combinations can drastically improve visual alignment across frames or scenes:
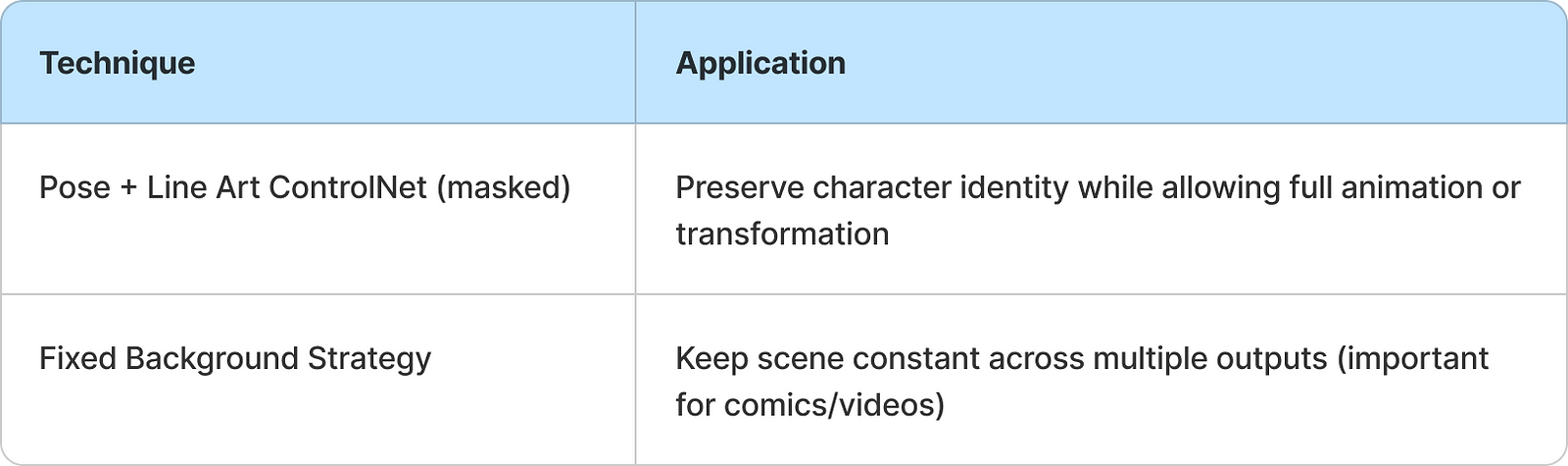
Prompting Templates & Strategy: This vs That
Crafting consistent characters is not just about creativity — it’s about precision. The way you phrase your prompt, structure your attributes, and guide the model makes the difference between a character who stays visually true… and one who morphs frame by frame.
Below are side-by-side comparisons of weak vs. strong prompting strategies — customized for different diffusion models and generation contexts.
1. Stable Diffusion XL (Image Gen)
Generate a clean, detailed portrait that locks in a character’s identity and visual style.
❌ Basic Prompt:
Girl with red hair and green jacket, city background, anime style

This generic prompt offers no anchor for consistency — hair color, pose, and expression can shift with every generation.
✅ Improved Prompt (with control strategy):
Portrait of a teenage girl with fiery red hair and emerald green leather jacket, standing still in a neon-lit Tokyo street, anime art style, front view, symmetrical face, sharp emerald eyes, seed=12345, ControlNet(line art)

Why It Works:
Precision language (“fiery red”, “emerald green”) helps reinforce identity.
Specific art style + background adds scene context.
Seed + ControlNet(line art) stabilizes pose and facial structure.
Works well when creating consistent comic panels or character cards.
2. Wan 2.1-Fun (Text/Image-to-Video Generation)
Create a short animated scene that keeps character features intact across frames.
❌ Basic Prompt:
A boy running through a forest
Too vague — visual drift in age, hair, motion, or even clothing is likely.
✅ Improved Prompt (video + pose control):
Young boy with messy black hair, cobalt blue hoodie, thin frame, running through a pine forest at golden hour, side-angle view, cinematic soft lighting, consistent proportions, Pose ControlNet enabled, reference image of base character embedded
Why It Works:
Combines a clear text identity with a pose reference, reducing motion distortion.
Maintains character proportions and consistent rendering of hair/facial features.
Best for narrative scenes with dynamic motion, like game intros or animated explainers.
3. AnimateDiff (Keyframe-Based Video Generation)
Show character movement (dance, action, gesture) while retaining facial structure and identity.
❌ Loose Prompt:
A girl dancing in a spotlight
No clarity on identity, style, or camera focus — expect jitter, changing background, and unstable facial features.
✅ Rich Prompt (with reference + background fix):
Close-up of teenage girl with shoulder-length brown hair and silver glitter outfit, dancing joyfully on a theater stage under a sharp spotlight, same face as reference image, animated in smooth steps, stage and lighting fixed, ControlNet(line art) applied to preserve pose and outfit
Why It Works:
Line Art ControlNet keeps the facial design and motion flow intact.
Background fixation avoids unwanted scene jitter.
Best for short reels, TikTok-style content, or music/dance loops.
4. Flux Model Trainer (Custom Trained Model for Reuse)
You want to reuse a comic protagonist or branded mascot across scenes, stories, or even product visuals — without regenerating from scratch each time.
✅ Strategy:
Train a model on 15–30 clean, expressive images of your character.
Use consistent angles, lighting, and styles.
Follow a repeatable prompt structure for all outputs.
Example Prompt (Post-Training):
Flux-trained model of Captain Nova, sleek silver armor with glowing neon blue visor, short spiky white hair, intense gaze, standing atop a city skyline at dusk, heroic pose, same art style, cinematic atmosphere

Why It Works:
Once trained, the model “remembers” Captain Nova’s identity — even across radically different scenes or outfits.
Perfect for graphic novels, animated series, or games where character fidelity matters.
Comparison Chart: Prompting Strategy by Model
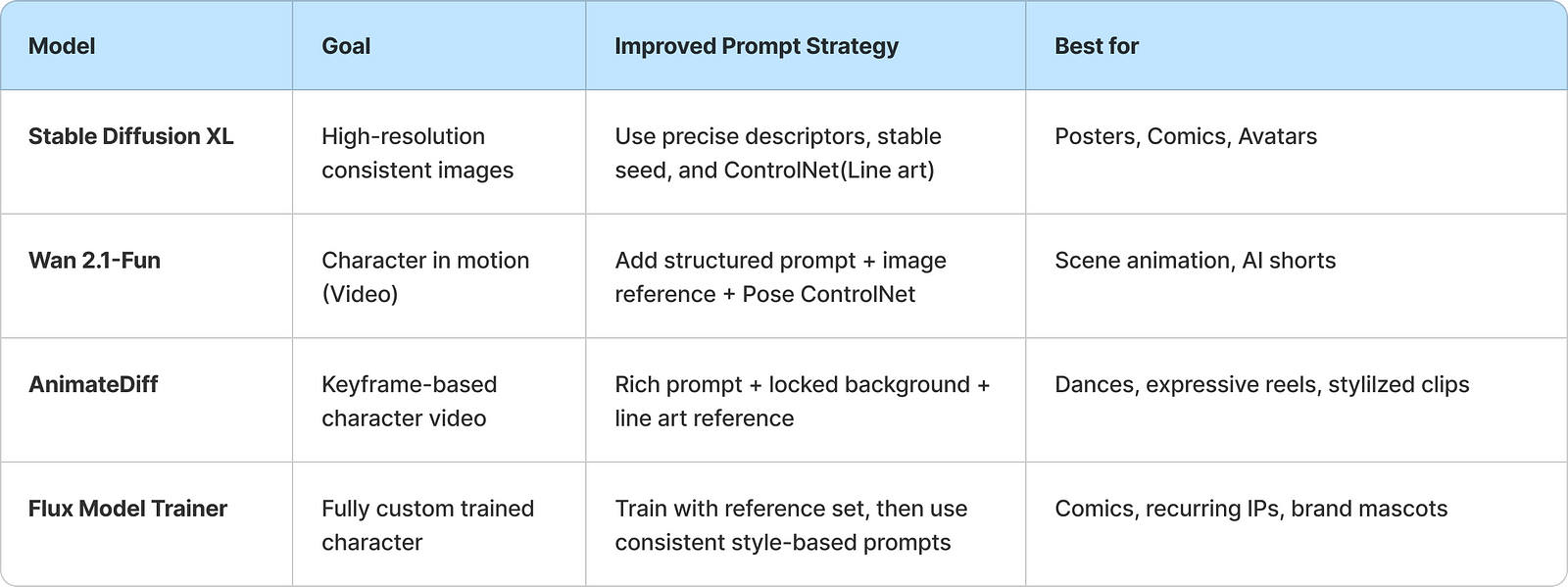
Pro Tips
Prompt = Blueprint
Treat your prompt like a spec sheet: the more repeatable, structured, and character-focused it is, the less visual drift you’ll experience.
Repeat Identity Elements
Terms like “neon visor,” “short silver hair,” or “red leather coat” should repeat exactly every time. Synonyms cause drift.
Fix Your Background When Possible
In animation, a stable background allows the model to focus more on evolving motion — rather than redrawing the environment every time.
Use ControlNet for Precision
Line Art = fix fine details
Pose = lock body motion
Depth = structure with flexibility
The Prompt Template that works
Different types of prompts serve different goals. Here’s a quick library of prompt templates with examples for common use cases.
Identity Prompt — Who are they?
This type of prompt defines the foundational traits of your character — physical appearance, accessories, and a hint of personality. These details act as the character’s “visual fingerprint,” anchoring consistency across outputs.
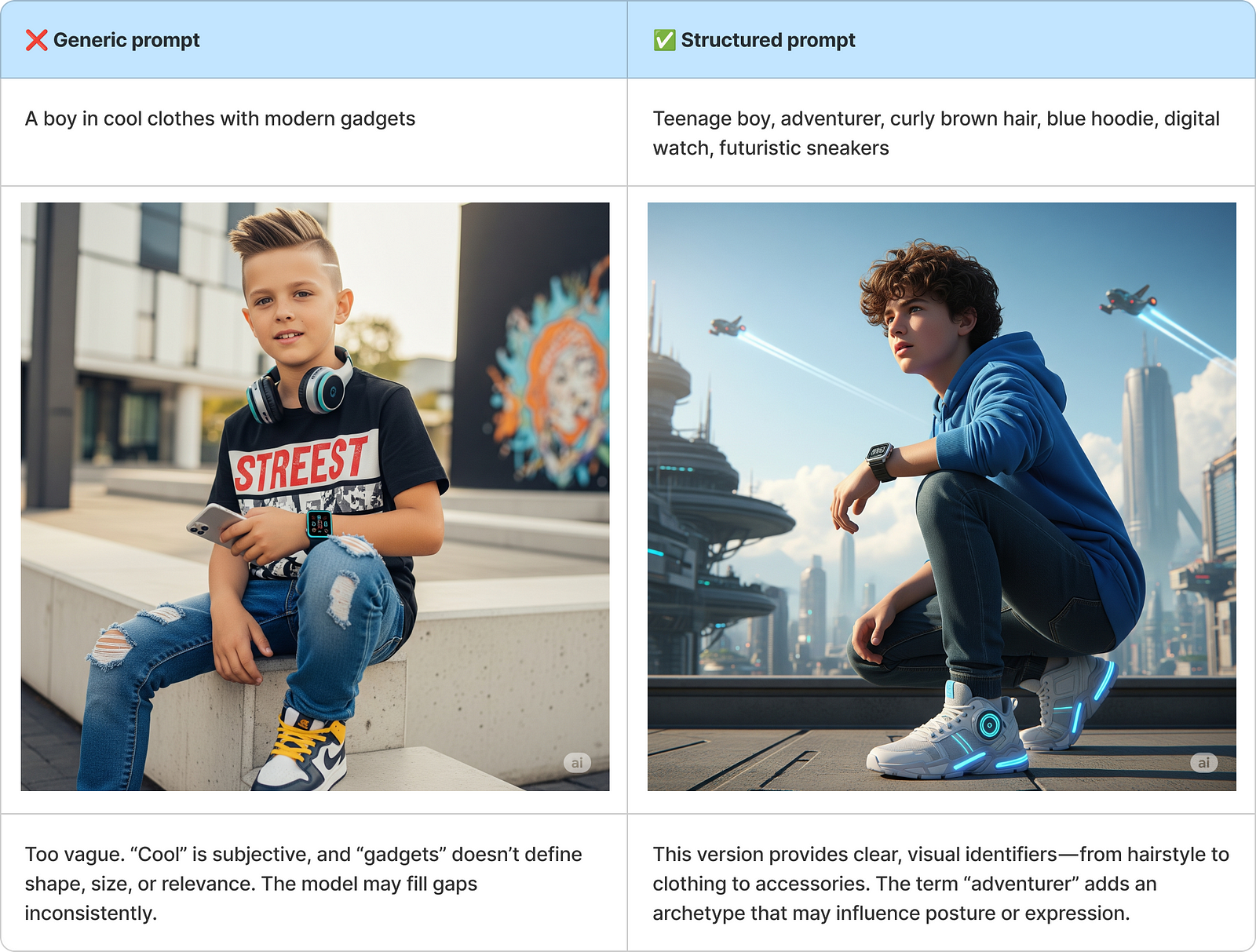
Why It Works: Specific, modular traits create a mental image the model can “remember” and repeat.
Scene-Based Prompt — Where are they, and what are they doing?
This prompt adds narrative and cinematic quality by blending identity with setting. It’s ideal for storytelling, comics, or video stills.
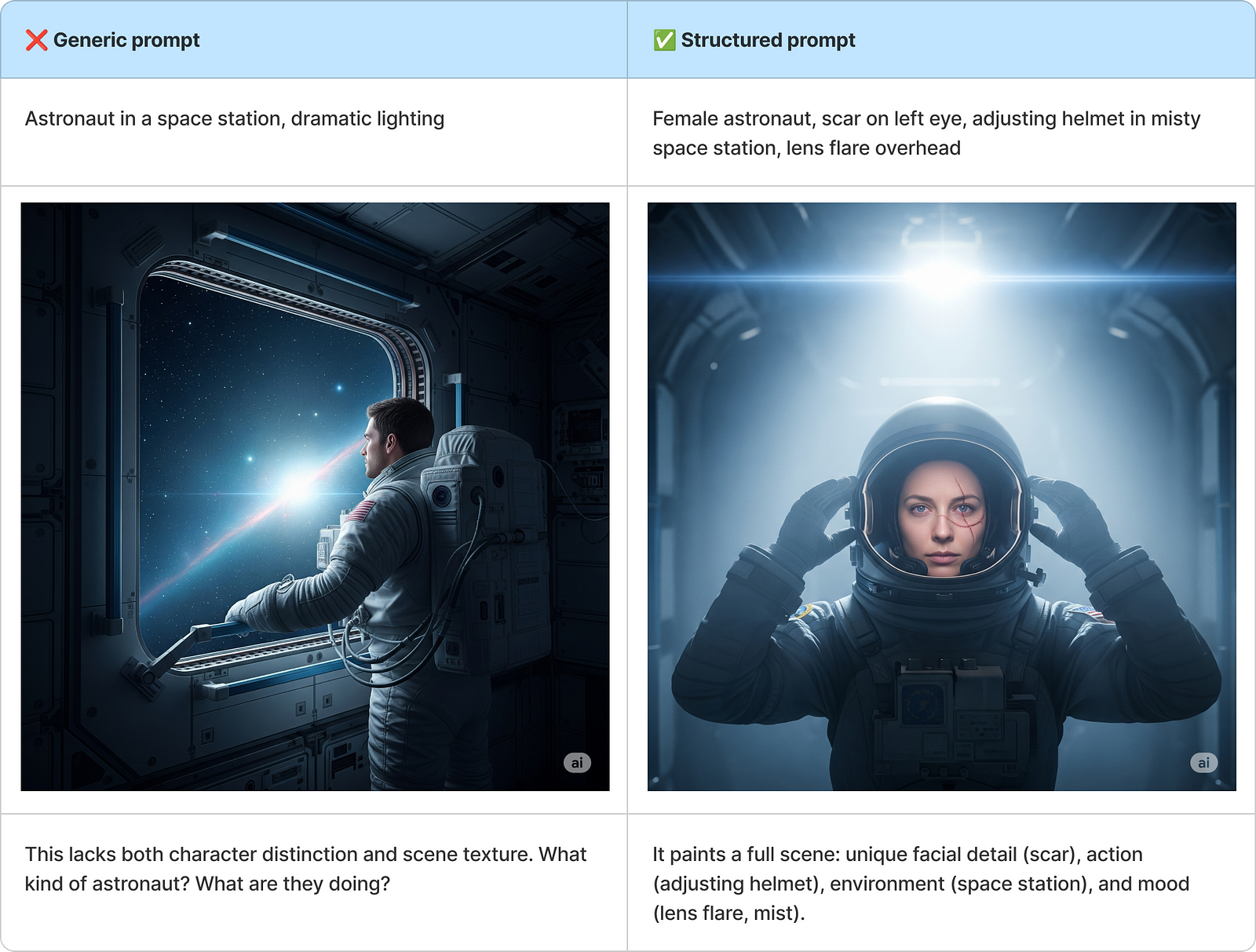
Why It Works: The prompt tells both the who and the where — without sacrificing either.
Mood / Emotion Prompt — What do they feel?
This type evokes inner emotion through subtle visual cues — posture, expression, environment, and light. It’s great for introspective scenes or emotional beats.

Why It Works: Emotion is built through action and atmosphere — not just labels.
Character-Focused Prompt — Style + Identity + Setting
This prompt type blends core traits, fashion, and backdrop, locking in identity while giving enough environmental context for reusability. It’s perfect for profile shots, branded art, or character intros.
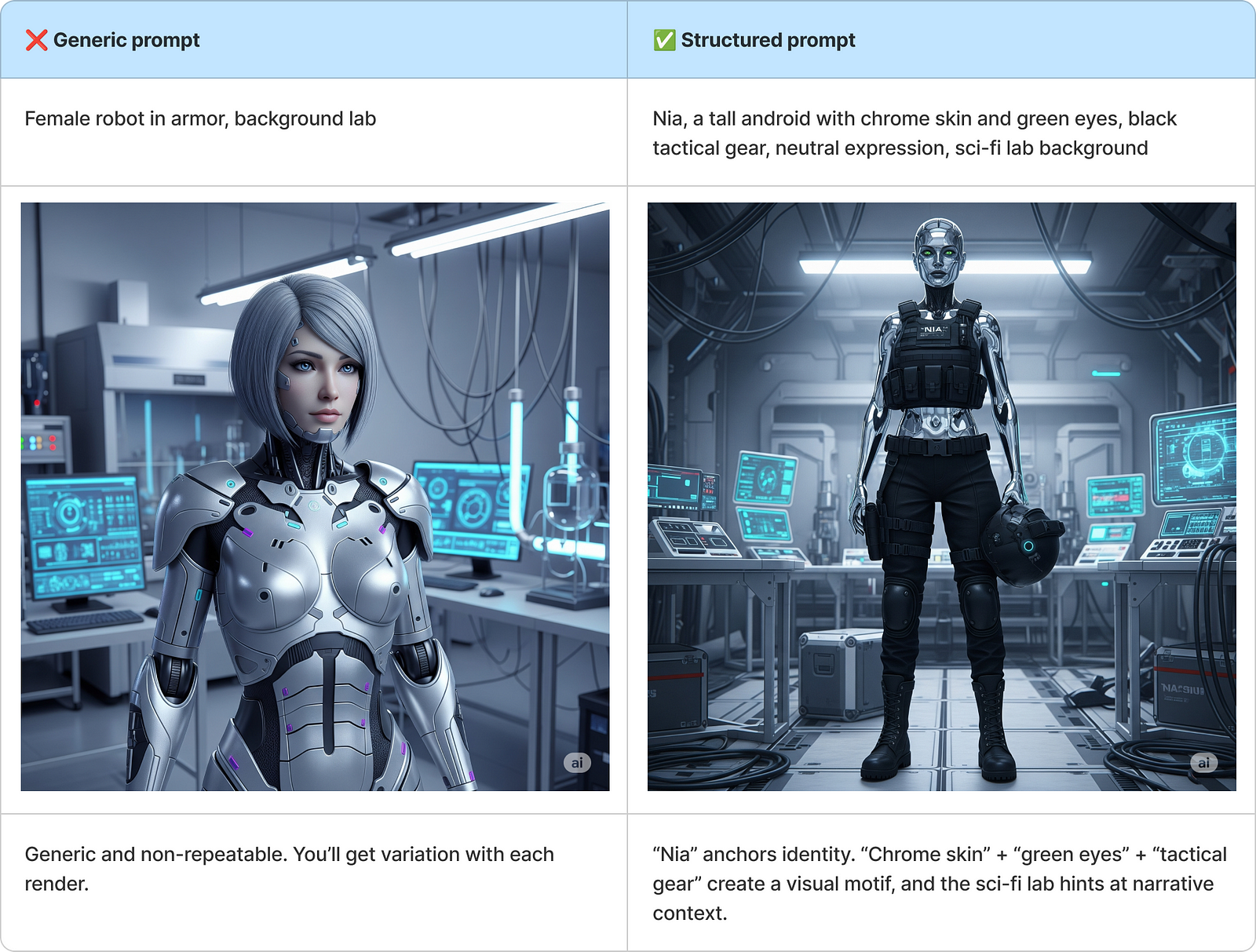
Why It Works: This structure builds a visually unique character in a contextually rich world, all in one shot.
Action Prompt — What are they doing in motion?
Action doesn’t mean chaos. This prompt preserves identity while adding kinetic energy — ideal for animation frames, key poses, or dynamic panels.
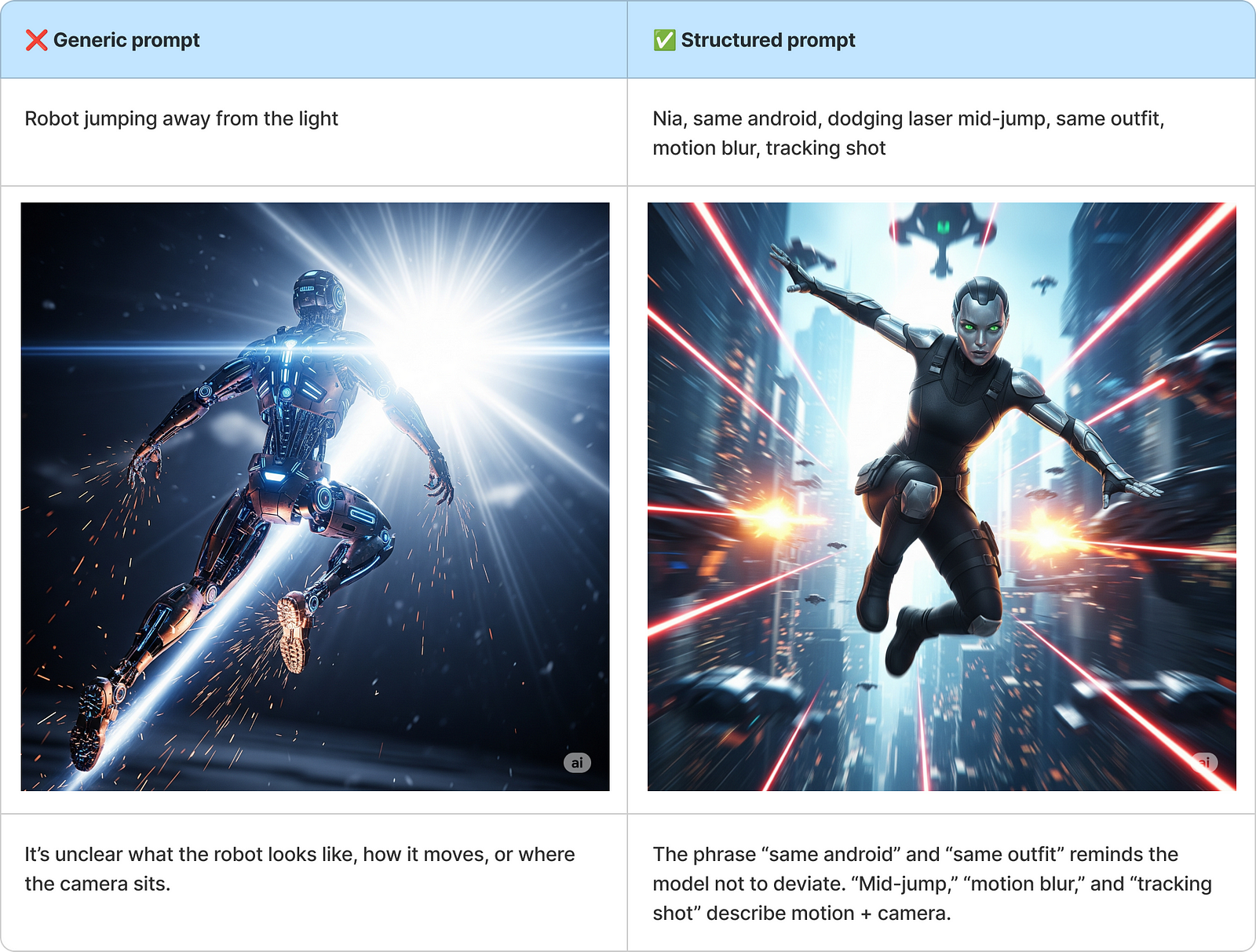
Why It Works: Structured motion plus repeated identity signals = fluid, consistent action visuals.
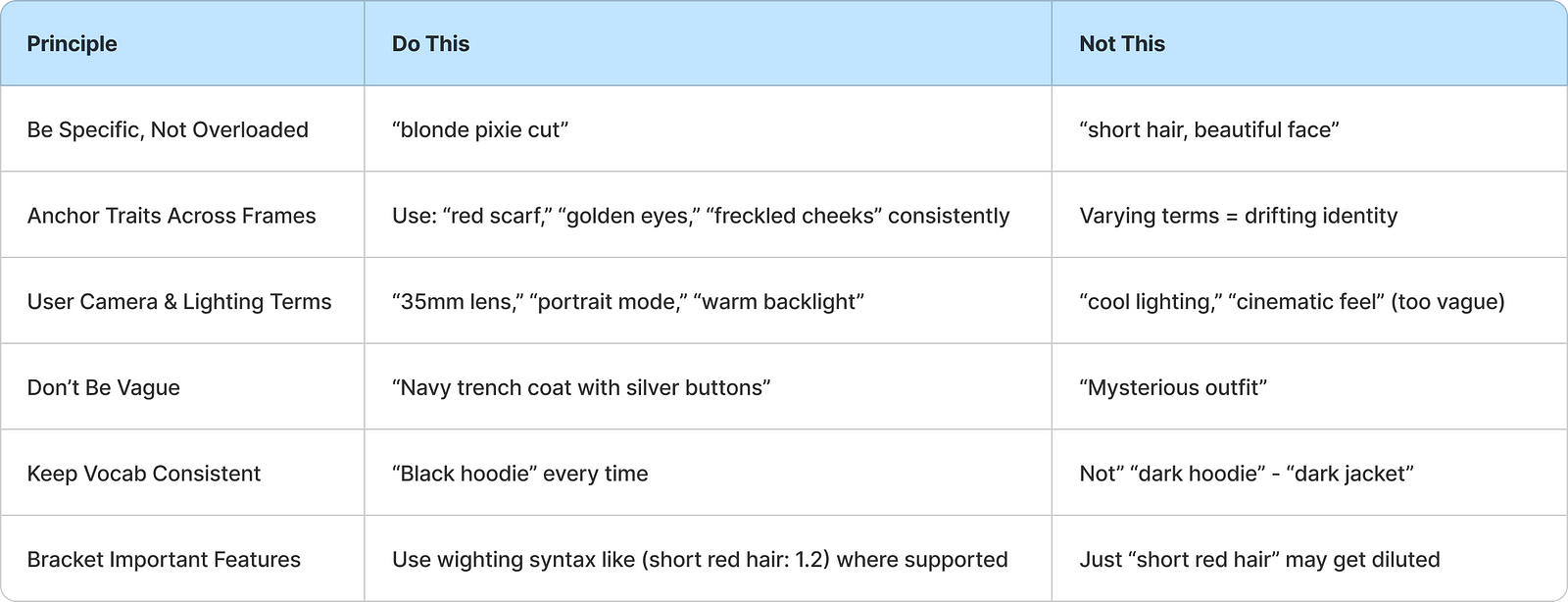
Prompting Tips: Small Things, Big Difference
Sometimes it’s not about writing more, but writing right.
Bringing It All Together
This isn’t about tricks. It’s about the method.
Creating a consistent AI character isn’t some secret sauce — it’s a set of repeatable steps: write structured prompts, reuse visual anchors, understand how diffusion models interpret inputs, and guide generation like a director on set.
Your characters deserve more than a lucky first frame. Give them structure. Give them memory. Give them identity.
Then hit “generate” — and let your cast shine, one frame at a time.
Enjoyed this? Hit to subscribe ❤️ and share your thoughts below.
Stay sharp. Stay creative.
Connect for more content:
shwetkaushal.com | LinkedIn | Instagram | Twitter | YouTube | Medium